
The volume of both users and generated data, along with the size and diversity of data, are expected to grow continuously. What can we do to handle this growth? Besides focusing on scalability and high availability, distributing data over large clusters, leveraging load balancers, and using distributed processing are all assets that are essential for big data projects so they can offer the business insights you need to stay competitive. We’ll go through each of them in this article and explain how they work, and why they are important.
Distributing Data Over Large Clusters
A big volume of data requires large processing capabilities, and the easiest way to do this massive processing is to distribute your data over large clusters. A single machine cannot store and process all the data of a company, and there are no other technical means to have all the data in one place to interrogate it, except for distributing it. It’s not difficult, if you have the knowledge required to do this. Some issues can arise if you’re just starting out, but they are all overcome by using the proper big data technologies.
Scalability
Closely related to distributing data over large clusters is scalability. Since a single event can thrive into having more and more data generated, your systems need to be able to adjust gradually, in time. With all the digitization efforts that we see happening across industries, we need our systems to become more scalable. Having scalable systems in place can greatly aid your business, but what is a scalable system? A system is scalable if it can handle quick changes to workloads and increase throughput as needed. Basically, if the system can grow along with the growth of your data volume and business itself.
Traditionally, scaling is done vertically with better hardware – better CPU, more RAM, extra disk space/storage - so we can process or store more. But this is not enough in most of the use cases we’ve seen. The scalability model proposed in such solutions is horizontal scaling – adding capacity, adding nodes of the same type, or even adding different types of nodes. When one single machine becomes saturated, just adding another node is more convenient than having a migration or upgrade project that we used to do with vertical scaling.
High Availability
Linked to scalability, availability represents the ability of a system to undertake administration and servicing without impacting end-user accessibility or the application uptime. High availability guarantees functional continuity – the capability to run your big data projects 24/7, which is especially important for real-time analysis.
By design, most of the solutions work this way and having high availability is a strong asset in big data projects, however, this architecture is valid not only for big data platforms, but also for Kubernetes or cloud computing. High availability clusters improve service uptime by providing uninterrupted service, and having data replicated over multiple nodes also provides redundant systems with no single points of failure (SPOF).
Load Balancing
Used in both hardware and software, load balancing minimizes response time and enhances throughput by spreading requests between two or more resources. How? Load balancing clusters automatically distribute or reroute incoming traffic from applications across multiple servers or nodes to spread the request load or to avoid unhealthy servers in production. This way, the fault tolerance of applications is also increased since all nodes in the cluster are active at the same time and offer the same capabilities to the end-user. Load balancing, together with failover solutions, ensures the much-needed redundancy and rapid disaster recovery.
Parallel to Distributed Processing
Regular processing works with parallel threads done on the same computing server (multiple processors process tasks simultaneously), while distributed processes/computing divides a task between multiple computers to achieve the same common goal (multiple devices process the same task). If your infrastructure where you add nodes is flexible enough, you can scale up or even down, or talk about a deployment in any of the clouds (GCP, AWS, Azure), so your system can process tasks faster.
With all this data changing, and with new business requirements that everything needs to be processed in real-time, processing speed becomes a real pain point for many businesses. Let’s say your systems manage to process data the next day or with a few hours’ delay using batch processing – this might sometimes not be good enough for the proper flow of your business.
With stream processing capabilities, or with the help of big data technologies, we see that it’s possible to do the same task almost in real-time with very low latencies. There are many possible solutions in this area, and big data can both improve operations workflow and offer faster time-to-market, among other benefits.
However, you shouldn’t dismiss batch processing as it’s still very valuable for ingesting historical data and it generally makes sense to use both types of processing strategies at the same time, for different business scopes.
Big Data Deployment Environments
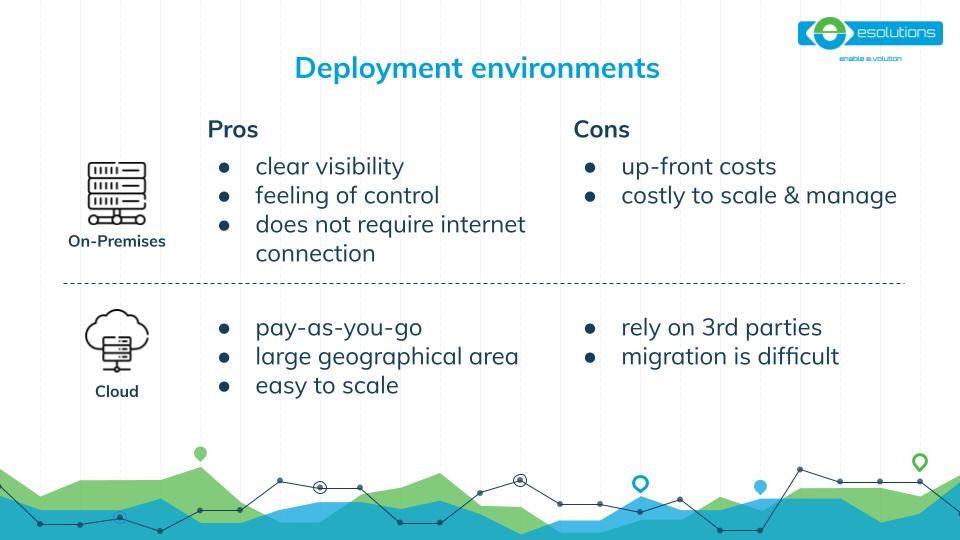
Finally, let’s discuss the hosting options for your big data project. Both on-premises and cloud hosting have pros and cons, so you need to figure out which solution will work best for you.
For instance, deploying your big data project on-premises means that you are in control of your systems and data, and from the point of view of security, you won’t have anything to worry about, as long as everything is set up correctly. You’ll also have full visibility into what’s going on with your data and the project itself. Nonetheless, hosting your big data project on-premises is overall very costly to manage at the onset of the project, and to scale long-term.
On the other hand, hosting your big data project in the cloud brings the advantages of paying only for what you use (namely the pay-as-you-go pricing plan), and it is way easier to scale than an on-premises infrastructure. Another benefit is that the public cloud covers a large geographical area. On the flip side, migration is quite difficult - since most vendors have the habit of making it difficult to switch from their services (aka vendor lock-in) - and you need to trust a 3rd party cloud provider with all your data.

Lastly, there is also the now popular hybrid hosting option, where you keep and analyze part of your data on-premises (perhaps the more sensitive data), and part of it in the public cloud, or multi-cloud, where you can use two or more public clouds, two or more private clouds, or a combination of public and private clouds.
Conclusion
We have worked with all three deployment environments, and we have experience in handling big data projects from start to finish according to our customers’ requests. High availability, scalability, data distribution, and the blend of batch and stream processing are essential for big data to work well and give you the insights and information your business needs to move forward. If you need help in starting a big data project, you can find more information about our services here.
About the Author

An enthusiastic writing and communication specialist, Andreea Jakab is keen on technology and enjoys writing about cloud platforms, big data, infrastructure, gaming, and more. In her role as Social Media & Content Strategist at eSolutions.tech, she focuses on creating content and developing marketing strategies for eSolutions’ social media platforms to maintain brand consistency.