
To quickly decide if this is for you, this article deals with 3 errors/alerts related to the etcd component of a Kubernetes cluster:
# in rancher web interface: alert component etcd is unhealthy
# docker logs etcd
panic: freepages: failed to get all reachable pages (page 6987: multiple references)
# docker logs etcd
rafthttp: request cluster ID mismatch ...
rafthttp: request sent was ignored (cluster ID mismatch: ...
We use Rancher 2.x to manage some of our Kubernetes clusters and this has a nice web interface. One day we got this alert / error about 'etcd is unhealthy'.
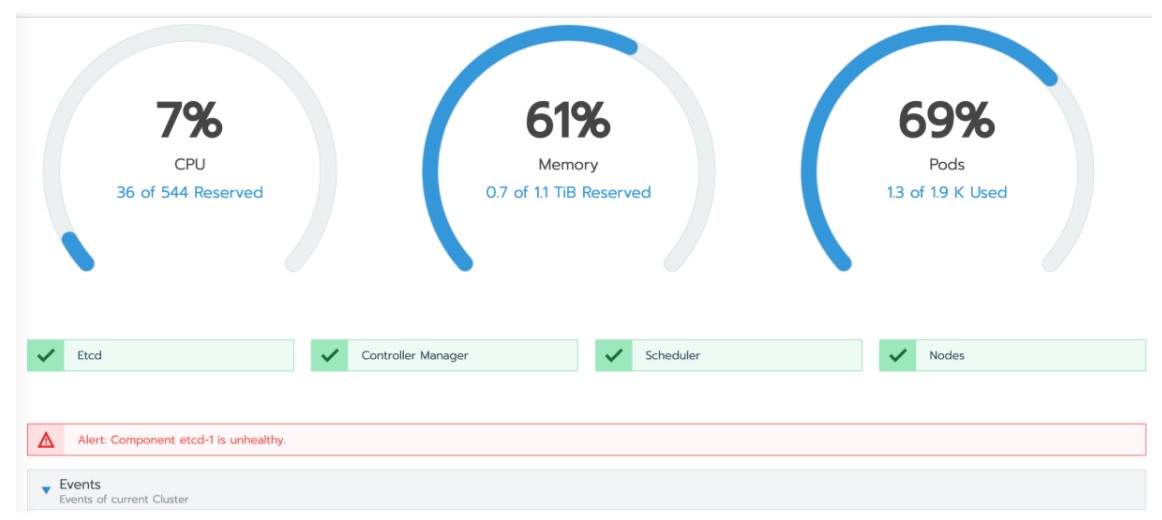
Etcd is the Kubernetes database and it holds basically all the cluster information. You can backup and restore a full cluster having only etcd data. Fortunately, etcd (usually) runs in a HA system with 3 nodes. But now we have one of the etcd nodes down, as can be confirmed with
$ kubectl get component status
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
etcd-1 Unhealthy Get "https://192.168.60.48:2379/health": dial tcp 192.168.60.48:2379: connect: connection refused
scheduler Healthy ok
controller-manager Healthy ok
etcd-2 Healthy {"health":"true"}
etcd-0 Healthy {"health":"true"}
This is a cluster installed directly from the Rancher interface, and by ssh-ing into that VM we can see etcd is running inside a docker container:
$ docker ps | grep etcd
5fb87452ddff rancher/coreos-etcd:v3.4.13-rancher1 "/usr/local/bin/etcd…"
6 months ago Restarting (2) 21 seconds ago
etcd
So, the container is not running ("Restarting"...). Looking in logs:
$ docker logs etcd
[...]
panic: freepages: failed to get all reachable pages (page 6987: multiple references)
goroutine 126 [running]:
go.etcd.io/bbolt.(*DB).freepages.func2(0xc0001c64e0)
/home/ANT.AMAZON.COM/leegyuho/go/pkg/mod/go.etcd.io/bbolt@v1.3.3/db.go:1003 +0xe5
created by go.etcd.io/bbolt.(*DB).freepages
/home/ANT.AMAZON.COM/leegyuho/go/pkg/mod/go.etcd.io/bbolt@v1.3.3/db.go:1001 +0x1b5
The container gets in the same state when trying to restart it (or docker container stop ...; docker container start ...).
Some online searches later, the general opinion was the etcd database is corrupt, probably by an unclean restart/shutdown and the etcd node must be recreated. It will start empty and will sync the database from the other nodes.
Yeey, that's seems simple and it is also confirmed by the official Rancher documentation at https://rancher.com/docs/rancher/v2.5/en/troubleshooting/kubernetes-components/etcd/#replacing-unhealthy-etcd-nodes where we find this:
"When a node in your etcd cluster becomes unhealthy, the recommended approach is to fix or remove the failed or unhealthy node before adding a new etcd node to the cluster."
and then the page ends. Wait! Wait!! How? How do we do that?? Well, back to online searches...
In the same Rancher documentation, at least, we find we can use etcdctl commands like this, on a working etcd node:
$ docker exec etcd etcdctl member list
b5f3d11f27cbc784, started, etcd-k1c1, https://192.168.60.47:2380, https://192.168.60.47:2379, false
d8c8687da4a99f58, started, etcd-k1c2, https://192.168.60.48:2380, https://192.168.60.48:2379, false
dd6d795b336a5dc7, started, etcd-k1c3, https://192.168.60.49:2380, https://192.168.60.49:2379, false
Ok, that will be useful later. We read more docs about etcd to find out how to remove and re-add a node. I have not been able to find info for our particular case but I think the process should be like this:
etcdctl member remove ...
docker container stop ... # the unhealthy etcd node
remove the data directory so the container will start with empty database
etcdctl member add ... # we need to check parameters
docker container start ... # the unhealthy etcd node
After some experiments and filling in the dots, as an example, our commands were:
1$ docker exec etcd etcdctl member list # on a working etcd node
1$ docker exec etcd etcdctl member remove c6d99083f92f060c
2$ docker container stop etcd # on the unhealthy etcd node
2$ rm -rf /var/lib/etcd/member/ # this is the host directory mounted in the etcd container 1$ docker exec etcd etcdctl member add etcd-vm5 --peer-urls=https://64.225.105.45:2380
# exactly as it was before when we saw it as etcdctl member list
2$ docker container start etcd
Success! Drinks!
Um, not really, not yet... Looking the container logs, we see a new error:
2021-07-30 06:56:50.766417 E | rafthttp: request cluster ID mismatch (got 1df875ec16cdadc0 want 2aafb0f5f954d734)
2021-07-30 06:56:50.795741 E | rafthttp: request cluster ID mismatch (got 1df875ec16cdadc0 want 2aafb0f5f954d734)
2021-07-30 06:56:50.798215 E | rafthttp: request sent was ignored (cluster ID mismatch: peer[55981658a5324937]=1df875ec16cdadc0, local=2aafb0f5f954d734)
2021-07-30 06:56:50.798893 E | rafthttp: request sent was ignored (cluster ID mismatch: peer
So our trick with docker stop; docker start was not enough. After some more online searching, we found out we need to start this container from zero and with some command line arguments changed! More exactly, we must change this argument:
from
"--initial-cluster-state=new"
to
"--initial-cluster-state=existing"
which kinda makes sense and seems logical.
We don't have the full docker run command used to start this container, but we can use docker inspect to find out all the details:
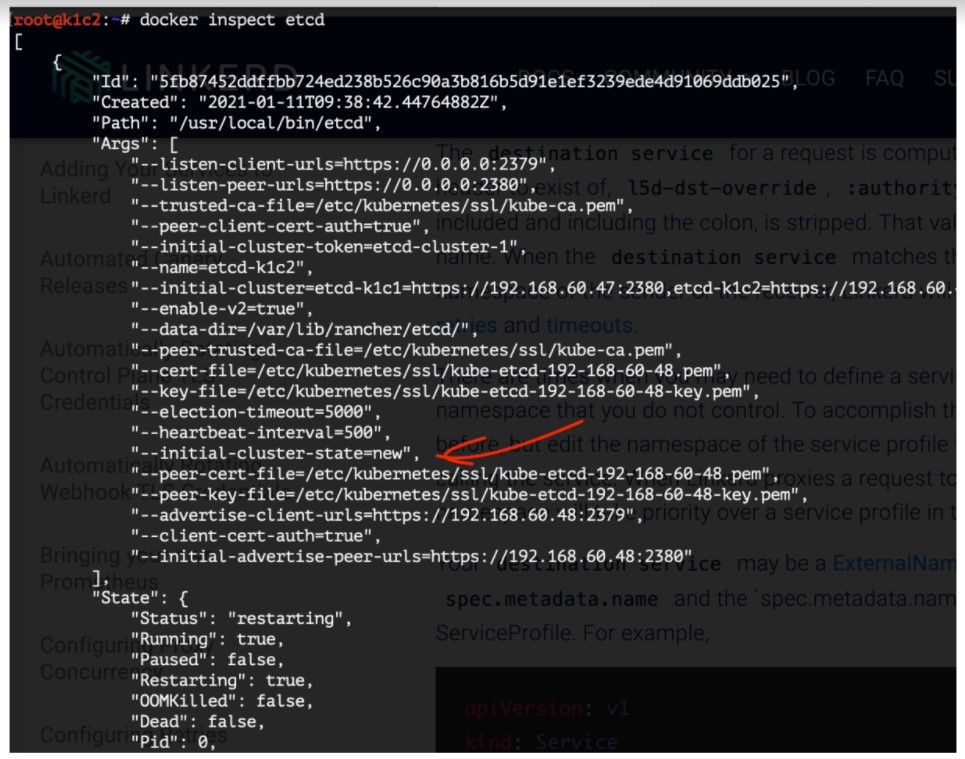
So, how can we create a docker run command from this? Either with hard work... or by online searching and finding this solution: https://gist.github.com/efrecon/8ce9c75d518b6eb863f667442d7bc679 . The file run.tpl is now also saved here: https://github.com/viorel-anghel/alert-component-etcd-is-unhealthy .
We save that file as run.tpl on the unhealthy node and finally we run
docker inspect etcd >docker-inspect-etcd-save.txt # save the info, just in case
docker inspect --format "$(<run.tpl)" etcd >docker-run-etcd # create the file with the docker run command
The resulted file will look something like:
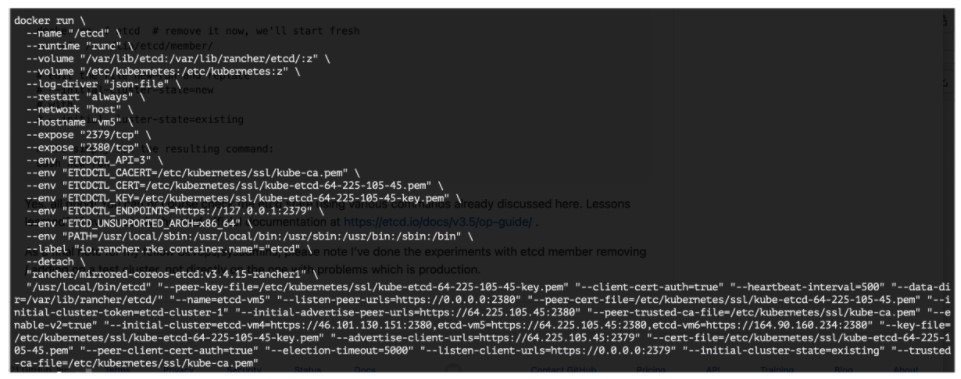
Now we just need to create the new container:
docker rm -f etcd # remove it now, we'll start fresh
rm -rf /var/lib/etcd/member/
# edit the file docker-run-etcd and replace
# --initial-cluster-state=new
# with
# --initial-cluster-state=existing
# the simply run the resulting command:
bash docker-run-etcd
Checking the etcd status with docker logs etcd, etcdctl member list, kubectl get componentstatus: yes, all good!
Lessons learned? I have to study the etcd official documentation at https://etcd.io/docs/v3.5/op-guide/ .
As a final advice for my fellow devops/sysadmins, please note I've done the experiments with etcd member removing / adding on a test cluster, not directly on the one with problems which is production.

Viorel Anghel has 20+ years of experience as an IT Professional, taking on various roles, such as Systems Architect, Sysadmin, Network Engineer, SRE, DevOps, and Tech Lead. He has a background in Unix/Linux systems administration, high availability, scalability, change, and config management. Also, Viorel is a RedHat Certified Engineer and AWS Certified Solutions Architect, working with Docker, Kubernetes, Xen, AWS, GCP, Cassandra, Kafka, and many other technologies. He is the Head of Cloud and Infrastructure at eSolutions.
Got a question or need advice? We're just one click away.